
You must have dealt with text files containing duplicate lines and words. The uniq tool is your best chance in Ubuntu where text files and redundant information are involved.
In Ubuntu, the uniq command is used to show duplicate lines in a text file. If you wish to eliminate identical words or lines from a text file, this command can assist. Because the uniq command looks for unnecessary copies by matching neighbouring lines, it can only be used with sorted text files.
In this tutorial, you will learn how to remove duplicate text from text files using the uniq command. You will also learn the full capabilities and options that the uniq command provides.
Prerequisites
- Ubuntu or any other Linux-based system
- Terminal access
Note: Although the commands used in this tutorial are for the Ubuntu system, all the methods are also valid for any other Linux-based system.
Uniq Command Basic Syntax
The uniq comes pre-installed in Ubuntu, so you do not need to install it. The uniq command's basic syntax is as follows:
uniq option input output
Input and output are the file paths of input and output files. And the different options are used to apply specific methods.
Find and Remove Duplicate Lines in Text File With uniq
For the next few commands, consider the following input text file.
Note: The example input files in this tutorial are already sorted. You can sort your files with the sort command before using uniq for correct results, as uniq needs sorted files as input.
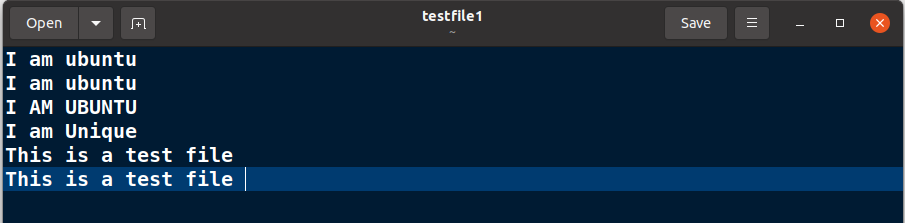
To find duplicates in a text file, run
uniq testfile1.txt

Handle Case Sensitivity While Searching For Duplicates
Consider testfile1 and the output of the above command. You can see that duplicates with different case sensitivity are not considered duplicates. To counter that, you can run the above command with the -i option.
uniq -i testfile1.txt

You can see that the case is ignored in the output.
Store uniq Command Output in a Separate File
You can save the uniq command output results in a separate file, so now you can start fresh with the duplication-free text.
Run the following command to save the output in a separate file. You can also run cat commands to see the contents of the resulting files.
uniq -i testfile1.txt > unique.txt

Count & Remove Duplicate Lines in Text Files With uniq
By running the uniq command with the -c option, you can count the duplication of a specific text in a file.
uniq -c testfile1.txt

You can see the number of times the line is repeated, in front of every line in the output.
Print Duplicate Lines in Text File With uniq
You can run the uniq command with the -D option to see the repeated text.
uniq -D testfile1.txt

Skip Fields While Searching For Duplicate Lines
If you need a little more flexibility while searching for duplicates and want to skip specific fields, you can do that with the -f option and field number.
uniq -f 1 testfile2.txt
Consider the following text file for this command.
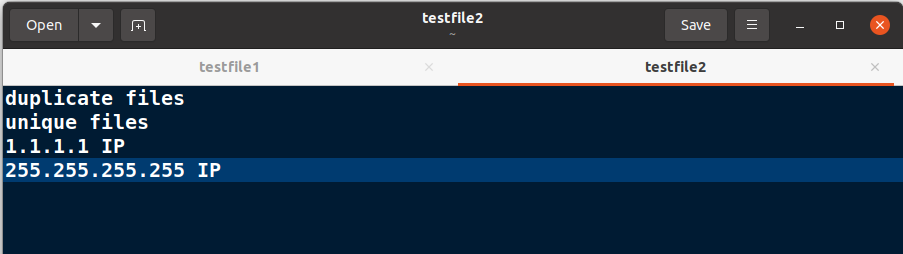

You can see in the output that the first field is ignored while comparing for duplicates.
Ignore Characters While Comparing Duplicate Lines
You can ignore fields with the above commands. Similarly, you can also skip characters while looking for duplicates.
uniq -s 2 testfile3.txt
Consider the listed text in the following file for this command.
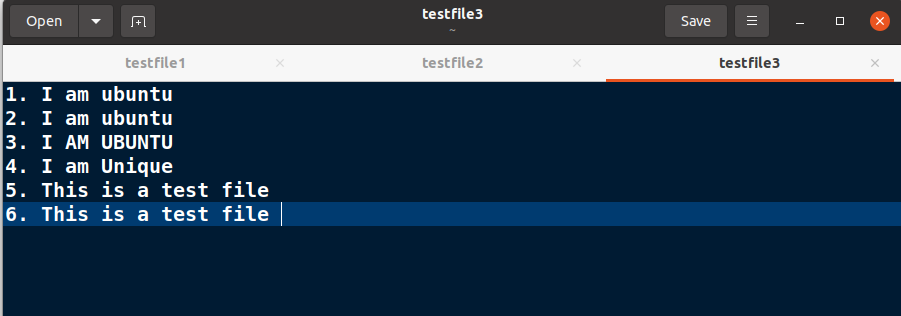
Run the uniq command with the -s option and the number of characters you want to ignore to skip characters in the duplicate search.

From the output, you can see that uniq has ignored the list numbering in the duplicate search.
Compare Selective Characters While Searching For Duplicate Lines
Uniq also offers to limit searches by the number of characters. To do a controlled search, run the following command with the number of characters you want to compare while comparing lines with each other.
uniq -w 4 testfile2.txt
Note: testfile1 is the input file for this command.

You can see repeated lines in the output because uniq has only compared the first four characters while searching for duplicates.
Conclusion
You'll spend the majority of your time managing Ubuntu servers on the terminal or editing text files. Working with text files can be frustrating if you do not know how to filter and sort text. As a result, learning from this article on how to delete unnecessary lines from a text file may be a valuable addition to your Ubuntu skill set.
Working with any sort of redundancy in files or within files is a test of patience. Ubuntu offers many tools and commands that can combat these issues. For example, you can use sed and awk commands to reduce duplication and redundancy within text files. Whereas, you can use Fdupes to search for and delete duplicate files in your system.